Trimming down pyarrow’s conda footprint (Part 2 of X)
·We have again reduced the footprint of creating a conda environment with pyarrow.
This time we have done some detective work on the package contents and removed contents from thrift-cpp and pyarrow that are definitely not needed at runtime.
In the last blog post about the pyarrow environment size, we already halved the size of the environment.
This time the improvement is a bit more than 10%, 48 MiB in absolute terms.
Still, this is a considerable reduction when looking forward that we also want to trim the basic pyarrow installation even more done.
Measuring the status quo
To see how well we can improve on the status quo, we will be measuring the size of the conda environment of different use cases:
- A basic Python installation from conda-forge:
conda create … python=3.8 -c conda-forge - Pandas without any optional dependencies:
conda create … python=3.8 pandas -c conda-forge - PyArrow with the same Python version:
conda create …python=3.8 pyarrow -c conda-forge - Pandas with the necessary parts of
pyarrowto read Parquet files:conda create … python=3.8 pyarrow pandas -c conda-forge(for now) - Nightly builds of
pyarrow:conda create .. python=3.8 pyarrow -c arrow-nightlies -c conda-forge
Overall this results in a bash script that creates these environments using the current latest versions from conda-forge:
#!/bin/bash
set -e
TIMESTAMP=$(date +%Y%m%d%H%M%S)
mkdir $(pwd)/$TIMESTAMP
conda create -p $(pwd)/$TIMESTAMP/baseline -y python=3.8 --override-channels -c conda-forge
conda create -p $(pwd)/$TIMESTAMP/pandas -y python=3.8 pandas --override-channels -c conda-forge
conda create -p $(pwd)/$TIMESTAMP/pyarrow -y python=3.8 pyarrow --override-channels -c conda-forge
conda create -p $(pwd)/$TIMESTAMP/parquet -y python=3.8 pyarrow pandas --override-channels -c conda-forge
conda create -p $(pwd)/$TIMESTAMP/pyarrow-nightly -y python=3.8 pyarrow --override-channels -c arrow-nightlies -c conda-forge
du -schl $(pwd)/$TIMESTAMP/* 2>/dev/null
With the changes of the previous blog post in place, we have a look at the above described conda environment at the timestamp 20200825110024, the state after the last blog post.
| Environment | Size |
|---|---|
| baseline | 147 MiB |
| pandas | 248 MiB |
| pyarrow | 413 MiB |
| parquet | 459 MiB |
| pyarrow-nigthly | 413 MiB |
Largest packages
The next attempt to minimise the size is to look at the largest packages by size in the pyarrow environment.
We can therefore use the DataFrame returned by the gather_files function we defined in the previous blog post.
With df.groupby("package")['size'].sum().sort_values().tail(10) // 1024 // 1024 we get the 10 largest packages with their size in megabytes:
| package | size in MiB |
|---|---|
| grpc-cpp | 11 |
| libstdcxx-ng | 12 |
| pyarrow | 13 |
| aws-sdk-cpp | 16 |
| numpy | 20 |
| libgcc-ng | 24 |
| libopenblas | 29 |
| thrift-cpp | 68 |
| python | 68 |
| arrow-cpp | 69 |
To visualise the contents of the package, we re-use the plot_size_by_suffix function to show the different file types that make up the individual packages.
![]()
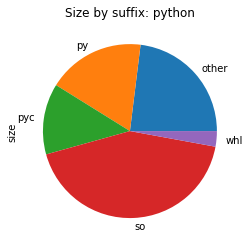
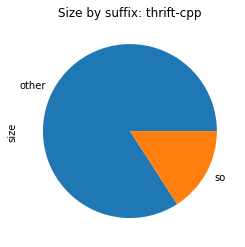


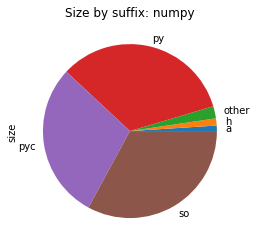
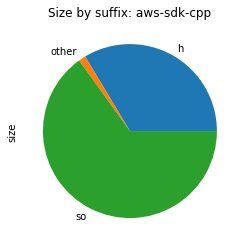
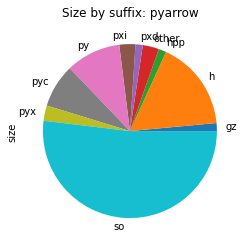

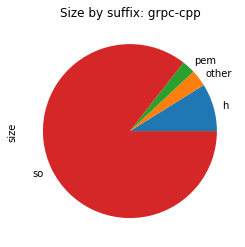
From the above images, we can see that in all those packages, most of the space is used for shared libraries or Python code.
There are two notable exceptions though.
pyarrow contains a vast array of different file types, hinting that we are shipping some intermediate build files. We will take a close look later.
First, we should have a look at what is causing thrift-cpp’s chart to report most of its space usage as “other”.
Most of thift-cpp is “other”
Given the DataFrame of of all files in the environment, we can query it for the 10 largest files in the thrift-cpp package using the following pandas code:
df_thrift = df.query("package == 'thrift-cpp'").sort_values(by="size")
df_thrift.tail(10)
| name | size | suffix |
|---|---|---|
include/thrift/protocol/TBinaryProtocol.tcc |
14413 | tcc |
include/thrift/protocol/TVirtualProtocol.h |
18241 | h |
include/thrift/protocol/TProtocol.h |
21174 | h |
include/thrift/transport/TBufferTransports.h |
22340 | h |
include/thrift/protocol/TCompactProtocol.tcc |
24075 | tcc |
include/thrift/server/TNonblockingServer.h |
30204 | h |
lib/libthriftz.so.0.13.0 |
1275240 | so |
lib/libthriftnb.so.0.13.0 |
1625160 | so |
lib/libthrift.so.0.13.0 |
8514392 | so |
bin/thrift |
60015752 |
Most of the files are no surprise, shared libraries and headers that define what is in the shared libraries.
One large outlier is the thrift binary though.
This is the thrift compiler that turns a Thrift definition into source code.
While this is needed during build, it is not relevant at runtime.
We work around this issue by splitting thrift-cpp into two conda packages: libthrift which contains everything needed at runtime and thrift-compiler that only contains the compiler.
pyarrow contains a vast set of file types
It is not necessarily bad to have a vast set of file types in a Python package with native code.
Especially as pyarrow is using Cython and also support building Cython modules on top of it.
We should just be careful that the package only ships with the files that are needed for the end-users and not any temporary files generated during the build.
As with the thrift-cpp package, we take a look at the list of largest files, in this case the top 30 as we are interested in variety of files.
df_pyarrow = df.query("package == 'pyarrow'").sort_values(by="size")
df_pyarrow['name'] = df_pyarrow['name'].str.slice(len("lib/python3.8/site-packages/pyarrow/"))
df_pyarrow.tail(30)
| name | size | suffix |
|---|---|---|
parquet.py |
71150 | py |
types.pxi |
71248 | pxi |
array.pxi |
71623 | pxi |
_orc.cpython-38-x86_64-linux-gnu.so |
71736 | so |
tests/test_dataset.py |
72714 | py |
includes/libarrow.pxd |
74732 | pxd |
tests/test_array.py |
83690 | py |
include/arrow/vendored/datetime/tz.h |
83883 | h |
_flight.pyx |
87232 | pyx |
_json.cpython-38-x86_64-linux-gnu.so |
89800 | so |
tests/__pycache__/test_parquet.cpython-38.pyc |
102754 | pyc |
include/arrow/util/bpacking_default.h |
103168 | h |
include/arrow/vendored/variant.hpp |
103300 | hpp |
tests/__pycache__/test_pandas.cpython-38.pyc |
117438 | pyc |
_hdfs.cpython-38-x86_64-linux-gnu.so |
125416 | so |
tests/test_parquet.py |
141698 | py |
tests/test_pandas.py |
145071 | py |
_s3fs.cpython-38-x86_64-linux-gnu.so |
156352 | so |
tests/data/orc/TestOrcFile.testDate1900.jsn.gz |
182453 | gz |
_compute.cpython-38-x86_64-linux-gnu.so |
213048 | so |
_csv.cpython-38-x86_64-linux-gnu.so |
223768 | so |
include/arrow/vendored/datetime/date.h |
229733 | h |
gandiva.cpython-38-x86_64-linux-gnu.so |
234912 | so |
_plasma.cpython-38-x86_64-linux-gnu.so |
237952 | so |
plasma-store-server |
322880 | |
_fs.cpython-38-x86_64-linux-gnu.so |
424208 | so |
_parquet.cpython-38-x86_64-linux-gnu.so |
448320 | so |
_dataset.cpython-38-x86_64-linux-gnu.so |
632408 | so |
_flight.cpython-38-x86_64-linux-gnu.so |
1005608 | so |
lib.cpython-38-x86_64-linux-gnu.so |
3219400 | so |
This actually contains many groups of files that shouldn’t be in the final package:
As the largest consumer of space, the tests/ folder including the test data is included.
While this is typical with a lot of packages, it takes more space in the pyarrow package than it does in other packages.
To get rid of them in the main package but still provide the end-users the possibility to run the tests locally to check their installation, we have introduced a new package pyarrow-tests in the PR upstream and on conda-forge.
There are two other bits that contribute a bit to the size but are also conceptually wrong in that they install things that are already installed by the arrow-cpp package.
This happens because pyarrow’s setup.py also caters for the case where the Python package is installed in a stand-alone fashion (e.g. when you install the pre-built wheels).
Then you also need to ship the relevant C++ parts.
But as we have the separate arrow-cpp package in the conda ecosystem, we don’t have a need for that in the pyarrow conda package.
The main thing here is that we reship the C++ headers in the …/site-packages/pyarrow/include/arrow folder while they are already installed in $CONDA_PREFIX/include.
To not install them, we introduced a new option for the setup.py called PYARROW_BUNDLE_ARROW_CPP_HEADERS that we can use to disable the vendoring of the includes in the Python package in the upstream PR and also backported that to the feedstock.
Additionally, we also ship the plasma-store-server binary in both the arrow-cpp and the pyarrow package.
As it is built as part of the C++ build, it’s natural home is the C++ package.
In the conda setting, it should also be placed on the PATH and thus reside in $CONDA_PREFIX/bin.
As we change the default location, we also adjusted the Python code that searches for it and also backported it into the conda package for the current release
With pyarrow and thrift-cpp cleaned up, at timestamp 20201026200633, we now observe the following sizes. Note that meanwhile new versions of most packages were released, thus the increase in the size of the pandas environment which we otherwise didn’t touch.
| Environment | Size | Reduction |
|---|---|---|
| baseline | 147MiB | 0% |
| pandas | 256 MiB | +3% |
| pyarrow | 365 MiB | -12% |
| parquet | 411 MiB | -10% |
| pyarrow-nigthly | 365 MiB | -12% |
Next steps
With the largest packages now cleaned from “suspicious” contents, we won’t see any significant changes anymore by looking at individual files.
Rather the next step will be to look at splitting packages, partly by their build- vs run-time components (discussion on that started in CFEP-20) and into their functional components.
The latter will be important especially for pyarrow / arrow-cpp as we often don’t need heavy-weights like Gandiva.
Splitting this off should give us a drastic improvement in the Parquet reading case above.
Title picture: Photo by ANDI WHISKEY on Unsplash