Trimming down pyarrow’s conda footprint (Part 1 of X)
·We have substantially reduced the footprint of creating a conda environment with pyarrow. While working on this, we have also substantially reduced the size of a base Python installation from conda-forge. All this was done without disabling any functionality. We reduced the size of a conda environment for pyarrow by nearly 50% and reduced the “pyarrow tax” for reading Parquet files with pandas to a tenth of its previous size. Additionally, we stripped 81MiB of unneeded files of every Python (3.8+) based conda environment installed from conda-forge.
Wes and others recently reduced the size of the pyarrow wheel by 75%.
As wheels are not the preferred choice of installing pyarrow but we as the Arrow developers continuously recommend to use conda (due to the large number of native dependencies of Arrow), I wanted to take a look at the installation size of pyarrow’s conda package. We prefer conda packages over wheels for the installation of pyarrow because conda manages the native dependencies explicitly. For the measurements, we’re are going to look at the size of the whole environment.
Measuring the status quo
To see how well we can improve on the status quo, we will be measuring the size of the conda environment of different use cases:
- A basic Python installation from conda-forge:
conda create … python=3.8 -c conda-forge - Pandas without any optional dependencies:
conda create … python=3.8 pandas -c conda-forge - PyArrow with the same Python version:
conda create …python=3.8 pyarrow -c conda-forge - Pandas with the necessary parts of
pyarrowto read Parquet files:conda create … python=3.8 pyarrow pandas -c conda-forge(for now) - Nightly builds of
pyarrow:conda create .. python=3.8 pyarrow -c arrow-nightlies -c conda-forge
Overall this results in a bash script that creates these environments using the current latest versions from conda-forge:
#!/bin/bash
set -e
TIMESTAMP=$(date +%Y%m%d%H%M%S)
mkdir $(pwd)/$TIMESTAMP
conda create -p $(pwd)/$TIMESTAMP/baseline -y python=3.8 --override-channels -c conda-forge
conda create -p $(pwd)/$TIMESTAMP/pandas -y python=3.8 pandas --override-channels -c conda-forge
conda create -p $(pwd)/$TIMESTAMP/pyarrow -y python=3.8 pyarrow --override-channels -c conda-forge
conda create -p $(pwd)/$TIMESTAMP/parquet -y python=3.8 pyarrow pandas --override-channels -c conda-forge
conda create -p $(pwd)/$TIMESTAMP/pyarrow-nightly -y python=3.8 pyarrow --override-channels -c arrow-nightlies -c conda-forge
du -schl $(pwd)/$TIMESTAMP/* 2>/dev/null
To measure the size of the components of the environments, we can use the information in the conda-meta/ folder. Here, conda has placed a JSON file per package with all the files that belong to it. The benefit of using this information over the simple file listing is that we later also can compute statistics on a per-package basis. The following Python script parses these JSON files, prints the total size of the environment and plots a pie chart of the environment size broken down by file suffix.
from pathlib import Path
import json
import pandas as pd
import matplotlib.pyplot as plt
def get_clean_suffix(name):
"""Get the filename suffix without numeric elements"""
suffixes = [x for x in name.split(".")[1:] if not x.isnumeric()]
return (suffixes or [""])[-1]
def gather_files(environment):
"""Gather the list of file in an environment"""
files = []
for meta in (environment / "conda-meta").glob('*.json'):
with meta.open("r") as f:
info = json.load(f)
for file in info["files"]:
path = (environment / file)
if not path.is_symlink():
files.append({
"package": info["name"],
"name": file,
"size": path.stat().st_size,
"suffix": get_clean_suffix(path.name)
})
return pd.DataFrame(files)
def plot_size_by_suffix(df, environment):
df_size = df.groupby('suffix').agg({
'size': 'sum',
'name': 'count'
}).rename({'name': 'count'}, axis=1).reset_index()
# Put suffixes that don't account for much into the "other" category
df_size.loc[df_size['size'] < 0.01 * df['size'].sum(), "suffix"] = ""
df_size.loc[df_size['suffix'] == "", "suffix"] = "other"
df_size = df_size.groupby("suffix").agg({
'size': 'sum',
'count': 'sum'
})
df_size["size"].plot.pie(title=f"Size by suffix: {environment}")
def print_env_report(date):
for env in date.glob("*"):
plt.figure()
df = gather_files(env)
print(f"Environment '{env}'\nsize: {df['size'].sum() // 1024 // 1024} MiB\n")
plot_size_by_suffix(df, env)
With this we get the following statistics for the timestamp 20200628092511:
date = Path("20200628092511/")
print_env_report(date)
| Environment | Size |
|---|---|
| baseline | 232 MiB |
| pandas | 339 MiB |
| pyarrow | 804 MiB |
| parquet | 804 MiB |
| pyarrow-nigthly | 787 MiB |
One can here already see the that the improvements that were made for the wheel are also reflected in the size of the nightly conda package.
Not only was there work on trimming the dependencies inside the wheel but also the code size of the compiled Arrow C++ code was massively optimised.
This already brings in a 17 MiB size reduction.
On the negative side, we can directly see that for reading Parquet files in pandas, the environment size increases by 465 MiB.
This means that for reading Parquet files, currently your pandas installation doubles in size.
To see where the size costs are actually spend, we break down the size by file type. While this is a very coarse representation of the environment, we can see a clear picture of what to address first.
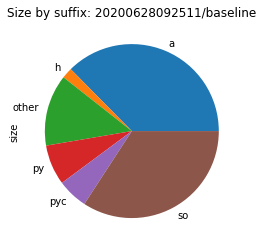
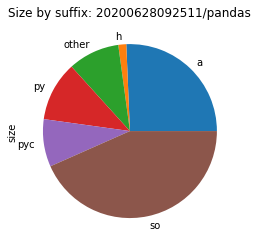
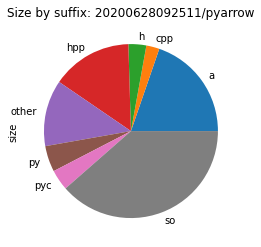
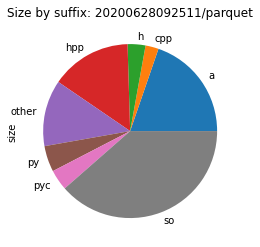
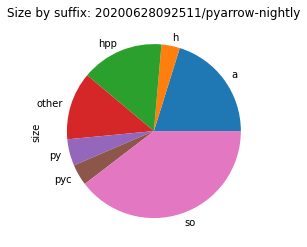
In most cases, a quarter of the size is spent for files with a suffix of .a.
These are static libraries that are used when linking together programs.
Static means here that the code that they contain is linked into a binary during compile time.
This is in contrast to shared objects (.so) where the code it loaded at runtime.
These static libraries are thus only useful when building native code, not when running it.
Therefore, they should not appear in environments that aren’t meant for building code.
CFEP-18: Standardise static libraries in conda-forge (get rid of them!)
As the static libraries are not contained in a single package but rather spread out over a large number of packages, getting rid of them is not as simple as removing them with a single rm **/*.a.
As there was yet no clear guideline on how to handle static archives in packages in conda-forge, I wrote a conda-forge enhancement proposal.
This resulted in CFEP-18 “packaging static libraries”.
The basic gist of this CFEP is: we avoid packaging and using static libraries in most cases. If we need them, we ship them as separate packages.
Removing the static libraries from an existing package is mostly as simple as deactivating them in the build, e.g. by using --disable-static in autotools based build.
In the case where we have a need for the static libraries, we have to introduce multiple outputs in the conda recipe.
One output for the general package, one that only contains the static library.
A possible approach for this is to separate the build into three scripts, one for building the code, two for installing the files.
In the installation script, the main package installs everything except the static library and the static library script installs everything.
As we make the static library package depend on the main package, conda-build will automatically only include the static library into the static library package.
This approach can be seen in the CFEP-18 PR for nghttp2.
The package with the most visible impact in the conda-forge ecosystem is that we removed the static libraries from the python package.
In combination the two static libraries libpython3.8.a and libpython3.8.nolto.a accounted for 81 of 149 MiB of the on-disk size.
Meanwhile, we also had a release of Arrow and thus we also see the improvements that were made in the size of the compiled Arrow binaries themselves.
No more boost runtime dependency
In addition to getting rid of static libraries, there is also the other easy win: Get rid of things that you actually don’t need.
One of the biggest Arrow dependencies is the Boost library.
It is also a dependency of Apache Thrift which in turn is needed for reading Parquet files.
Both of them need Boost at compile time but actually only the parts of Boost that are header-only.
They don’t depend on the (shared) libraries that are part of the boost-cpp package.
Thus we instruct conda-build to not export the build-time dependency of boost-cpp as a runtime dependency:
build:
ignore_run_exports:
- boost-cpp
Additionally, we had an unconditional dependency on pandas in the pyarrow requirements.
As most of pyarrow works without it, we remove it.
This reflects the requirements situation as defined in the Python package itself.
Final Numbers
With all these changes in place, we have a look at the above described conda environment at the timestamp 20200825110024.
| Environment | Size | Reduction |
|---|---|---|
| baseline | 147 MiB | -36% |
| pandas | 248 MiB | -27% |
| pyarrow | 413 MiB | -49% |
| parquet | 459 MiB | -43% |
| pyarrow-nigthly | 413 MiB | -48% |
While these aren’t the same numbers as with the wheel size, given that this is the total environment and conda packages of pyarrow are getting more love, they are still very impressive.
Next steps
While we have some nice improvements in environment size with removing static libraries and trimming down the dependencies, we still are far away from the perfect size.
As there are still some improvements possible that could have significant impact on the environment size, I’ll revisit this topic in future.
Some of the possible improvements include using link-time-optimisation for all dependencies and Arrow itself, splitting the arrow-cpp / pyarrow package into more packages, e.g. pyarrow.parquet for only the Parquet reading functionality, and also evaluating the contents of the dependencies whether they include any development resources that aren’t required during runtime.
Title picture: Photo by ANDI WHISKEY on Unsplash